
Bởi: Vitalik Buterin
Biên soạn bởi: Saoirse, Foresight News
Ngày nay, việc sử dụng bằng chứng không kiến thức để bảo vệ quyền riêng tư trong các hệ thống nhận dạng kỹ thuật số đã trở nên khá phổ biến. Nhiều dự án hộ chiếu không kiến thức đang phát triển các gói phần mềm cực kỳ thân thiện với người dùng, cho phép người dùng chứng minh rằng họ có ID hợp lệ mà không tiết lộ bất kỳ thông tin chi tiết nào về danh tính của họ. World ID (trước đây là Worldcoin), sử dụng sinh trắc học để xác minh và bằng chứng không kiến thức để bảo vệ quyền riêng tư, gần đây đã vượt qua 10 triệu người dùng. Một dự án nhận dạng kỹ thuật số của chính phủ tại Đài Loan sử dụng bằng chứng không kiến thức và Liên minh Châu Âu cũng đang chú ý nhiều hơn đến bằng chứng không kiến thức trong công việc nhận dạng kỹ thuật số của mình.
Trên bề mặt, việc áp dụng rộng rãi các danh tính kỹ thuật số dựa trên công nghệ bằng chứng không kiến thức có vẻ là một chiến thắng lớn cho d/acc. Nó có thể bảo vệ phương tiện truyền thông xã hội, hệ thống bỏ phiếu và nhiều dịch vụ Internet khác của chúng ta khỏi các cuộc tấn công của phù thủy và thao túng của robot mà không ảnh hưởng đến quyền riêng tư. Nhưng liệu có thực sự đơn giản như vậy không? Liệu vẫn còn rủi ro với các danh tính dựa trên bằng chứng không kiến thức? Bài viết này sẽ làm rõ các điểm sau:
- Kỹ thuật đóng gói không kiến thức (ZK-wrapping) giải quyết được nhiều vấn đề quan trọng.
- Vẫn còn những rủi ro trong danh tính được đóng gói với bằng chứng không kiến thức. Những rủi ro này dường như không liên quan nhiều đến sinh trắc học hoặc hộ chiếu. Hầu hết các rủi ro (rò rỉ quyền riêng tư, dễ bị ép buộc, lỗi hệ thống, v.v.) chủ yếu đến từ việc duy trì cứng nhắc thuộc tính "một người, một danh tính".
- Một thái cực khác, sử dụng "Bằng chứng về sự giàu có" để chống lại các cuộc tấn công Sybil, là không đủ trong hầu hết các tình huống ứng dụng, do đó chúng ta cần một số loại giải pháp "gần giống danh tính".
- Lý tưởng về mặt lý thuyết nằm ở đâu đó ở giữa, trong đó chi phí để có được N danh tính là N².
- Trạng thái lý tưởng này khó đạt được trong thực tế, nhưng "nhiều danh tính" phù hợp gần với trạng thái lý tưởng này và do đó là giải pháp thực tế nhất. Nhiều danh tính có thể là rõ ràng (chẳng hạn như danh tính dựa trên biểu đồ xã hội) hoặc ngầm định (nhiều loại danh tính bằng chứng không kiến thức cùng tồn tại và không có loại nào có thị phần gần 100%).
Cơ chế hoạt động của danh tính được gói gọn không cần chứng minh kiến thức là như thế nào?
Hãy tưởng tượng bạn có thể nhận được World ID bằng cách quét nhãn cầu hoặc nhận được hộ chiếu chứng minh không có kiến thức bằng cách quét hộ chiếu bằng đầu đọc NFC của điện thoại. Đối với mục đích của bài viết này, các thuộc tính cốt lõi của cả hai phương pháp đều giống nhau (chỉ có một vài điểm khác biệt nhỏ, chẳng hạn như nhiều quốc tịch).
Trên điện thoại của bạn, có một giá trị bí mật s. Trong sổ đăng ký toàn cầu trên chuỗi, có một giá trị băm công khai H(s). Khi bạn đăng nhập vào ứng dụng, bạn tạo một ID người dùng cụ thể cho ứng dụng, H(s, app_name) và xác minh thông qua bằng chứng không kiến thức rằng ID này và giá trị băm công khai trong sổ đăng ký có nguồn gốc từ cùng một giá trị bí mật s. Do đó, mỗi giá trị băm công khai chỉ có thể tạo một ID cho mỗi ứng dụng, nhưng nó sẽ không bao giờ tiết lộ giá trị băm công khai nào mà một ID ứng dụng cụ thể tương ứng.
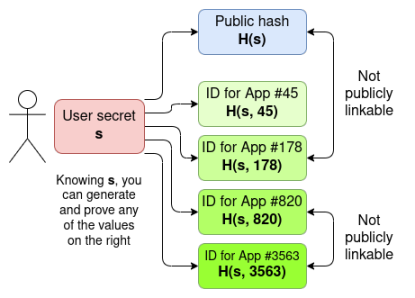
Trên thực tế, thiết kế có thể phức tạp hơn. Trong World ID, ID dành riêng cho ứng dụng thực sự là giá trị băm chứa ID ứng dụng và ID phiên, do đó các hoạt động khác nhau trong cùng một ứng dụng cũng có thể được tách rời khỏi nhau. Thiết kế dựa trên hộ chiếu bằng chứng không kiến thức cũng có thể được xây dựng theo cách tương tự.
Trên thực tế, thiết kế có thể phức tạp hơn. Trong World ID, ID dành riêng cho ứng dụng thực sự là giá trị băm chứa ID ứng dụng và ID phiên, do đó các hoạt động khác nhau trong cùng một ứng dụng cũng có thể được tách rời khỏi nhau. Thiết kế dựa trên hộ chiếu bằng chứng không kiến thức cũng có thể được xây dựng theo cách tương tự.
Trước khi đi sâu vào những nhược điểm của loại danh tính này, điều quan trọng là phải nhận ra những lợi ích mà nó mang lại. Ngoài phạm vi danh tính không cần chứng minh kiến thức (ZKID), bạn phải tiết lộ toàn bộ danh tính hợp pháp của mình để chứng minh bản thân với các dịch vụ yêu cầu xác thực. Đây là hành vi vi phạm nghiêm trọng “nguyên tắc đặc quyền tối thiểu” trong bảo mật máy tính: một quy trình chỉ nên có các quyền và thông tin tối thiểu cần thiết để hoàn thành nhiệm vụ của mình. Họ cần chứng minh rằng bạn không phải là rô-bốt, rằng bạn trên 18 tuổi hoặc rằng bạn đến từ một quốc gia cụ thể, nhưng những gì họ nhận được là một con trỏ đến danh tính đầy đủ của bạn.
Cải tiến tốt nhất có thể đạt được hiện nay là sử dụng các mã thông báo gián tiếp như số điện thoại và số thẻ tín dụng: trong trường hợp này, thực thể biết mối liên hệ giữa số điện thoại/thẻ tín dụng của bạn và các hoạt động trong ứng dụng được tách biệt khỏi thực thể (công ty hoặc ngân hàng) biết mối liên hệ giữa số điện thoại/thẻ tín dụng của bạn và danh tính hợp pháp. Nhưng sự tách biệt này cực kỳ mong manh: số điện thoại, giống như các loại thông tin khác, có thể bị rò rỉ bất cứ lúc nào.
Với sự trợ giúp của công nghệ đóng gói bằng chứng không kiến thức (ZK-wrapping, một phương tiện kỹ thuật bảo vệ quyền riêng tư danh tính người dùng bằng cách sử dụng bằng chứng không kiến thức, cho phép người dùng chứng minh danh tính của họ mà không tiết lộ thông tin nhạy cảm), các vấn đề trên đã được giải quyết phần lớn. Nhưng điều tôi muốn thảo luận tiếp theo là một điểm ít được đề cập đến: vẫn còn một số vấn đề không chỉ chưa được giải quyết mà thậm chí có thể trở nên trầm trọng hơn do giới hạn "một người, một danh tính" nghiêm ngặt của các giải pháp như vậy.
Chỉ riêng bằng chứng không kiến thức không thể đạt được tính ẩn danh
Giả sử rằng một nền tảng chứng minh danh tính không kiến thức (ZK-identity) hoạt động chính xác như mong đợi, tái tạo nghiêm ngặt tất cả các logic trên và thậm chí tìm ra cách bảo vệ thông tin riêng tư của người dùng không chuyên trong thời gian dài mà không cần dựa vào các tổ chức tập trung. Nhưng đồng thời, chúng ta có thể đưa ra một giả định thực tế: các ứng dụng sẽ không tích cực hợp tác với bảo vệ quyền riêng tư, chúng sẽ tuân thủ nguyên tắc "thực dụng", và các giải pháp thiết kế mà chúng áp dụng, mặc dù dưới biểu ngữ "tối đa hóa sự tiện lợi của người dùng", dường như luôn thiên về lợi ích chính trị và thương mại của riêng chúng.
Trong một kịch bản như vậy, các ứng dụng truyền thông xã hội sẽ không sử dụng các thiết kế phức tạp như khóa phiên thường xuyên thay đổi, mà sẽ chỉ định cho mỗi người dùng một ID ứng dụng cụ thể duy nhất và vì hệ thống nhận dạng tuân theo quy tắc "một người, một danh tính", người dùng chỉ có thể có một tài khoản (điều này trái ngược với "ID yếu" ngày nay, chẳng hạn như tài khoản Google, nơi một người trung bình có thể dễ dàng đăng ký khoảng 5 tài khoản). Trong thế giới thực, tính ẩn danh thường yêu cầu nhiều tài khoản: một tài khoản cho "danh tính thông thường" và các tài khoản khác cho nhiều danh tính ẩn danh khác nhau (xem " finsta và rinsta "). Do đó, trong mô hình này, tính ẩn danh thực tế mà người dùng có thể đạt được có khả năng thấp hơn mức hiện tại. Theo cách này, ngay cả một hệ thống "một người, một danh tính" được bao bọc trong bằng chứng không kiến thức cũng có thể dần đưa chúng ta đến một thế giới mà mọi hoạt động phải được gắn với một danh tính công khai duy nhất. Trong thời đại rủi ro ngày càng tăng (như giám sát bằng máy bay không người lái), việc tước đi khả năng tự bảo vệ mình của mọi người thông qua tính ẩn danh sẽ gây ra hậu quả tiêu cực nghiêm trọng.
Chỉ riêng bằng chứng không kiến thức không thể bảo vệ bạn khỏi sự ép buộc
Ngay cả khi bạn không tiết lộ giá trị bí mật của mình, không ai có thể thấy các kết nối công khai giữa các tài khoản của bạn, nhưng nếu ai đó buộc bạn phải tiết lộ thì sao? Chính phủ có thể buộc bạn tiết lộ giá trị bí mật của mình để họ có thể thấy mọi hoạt động của bạn. Đây không phải là lời hứa suông: chính phủ Hoa Kỳ đã bắt đầu yêu cầu người nộp đơn xin thị thực tiết lộ tài khoản mạng xã hội của họ. Ngoài ra, người sử dụng lao động có thể dễ dàng biến việc tiết lộ toàn bộ hồ sơ công khai thành điều kiện tuyển dụng. Ngay cả các ứng dụng riêng lẻ về mặt kỹ thuật cũng có thể yêu cầu người dùng tiết lộ danh tính của họ trên các ứng dụng khác trước khi họ được phép đăng ký (điều này được thực hiện theo mặc định khi đăng nhập bằng ứng dụng).

Tương tự như vậy, trong những trường hợp này, giá trị của thuộc tính bằng chứng không kiến thức bị mất, nhưng những bất lợi của thuộc tính mới "một người, một tài khoản" vẫn tồn tại.
Tương tự như vậy, trong những trường hợp này, giá trị của thuộc tính bằng chứng không kiến thức bị mất, nhưng những bất lợi của thuộc tính mới "một người, một tài khoản" vẫn tồn tại.
Chúng ta có thể giảm thiểu rủi ro ép buộc thông qua tối ưu hóa thiết kế: ví dụ, sử dụng cơ chế tính toán đa bên để tạo ID duy nhất cho mỗi ứng dụng, cho phép người dùng và nhà cung cấp dịch vụ tham gia vào đó. Theo cách này, nếu không có sự tham gia của nhà điều hành ứng dụng, người dùng không thể chứng minh ID duy nhất của họ trong ứng dụng. Điều này sẽ làm tăng độ khó trong việc buộc người khác tiết lộ toàn bộ danh tính của họ, nhưng không thể loại bỏ hoàn toàn khả năng này và các giải pháp như vậy có những nhược điểm khác, chẳng hạn như yêu cầu nhà phát triển ứng dụng phải là các thực thể hoạt động theo thời gian thực, thay vì các hợp đồng thông minh thụ động trên chuỗi (không can thiệp liên tục).
Chỉ riêng bằng chứng không kiến thức không thể giải quyết được các rủi ro không liên quan đến quyền riêng tư
Mọi hình thức nhận dạng đều có những trường hợp ngoại lệ:
- Giấy tờ tùy thân do chính phủ cấp, bao gồm hộ chiếu, không áp dụng cho những người không quốc tịch hoặc những người chưa có các loại giấy tờ này.
- Mặt khác, các hệ thống nhận dạng do chính phủ quản lý mang lại những đặc quyền riêng cho những người sở hữu nhiều quốc tịch.
- Các cơ quan cấp hộ chiếu có thể bị tấn công, và các cơ quan tình báo ở các quốc gia thù địch thậm chí có thể tạo ra hàng triệu danh tính giả (để thao túng các cuộc bầu cử, ví dụ, nếu "bầu cử du kích" theo kiểu Nga trở nên phổ biến).
- Đối với những người có thông tin sinh trắc học liên quan bị suy giảm do chấn thương hoặc bệnh tật, nhận dạng sinh trắc học sẽ hoàn toàn không có hiệu quả.
- Nhận dạng sinh trắc học dễ bị kẻ làm giả mạo. Nếu giá trị của nhận dạng sinh trắc học trở nên cực kỳ cao, chúng ta thậm chí có thể thấy mọi người nuôi cấy các bộ phận cơ thể người chỉ để "sản xuất hàng loạt" những nhận dạng như vậy.
Những trường hợp ngoại lệ này có hại nhất trong các hệ thống cố gắng duy trì đặc tính "một người, một danh tính" và chúng không liên quan gì đến quyền riêng tư. Do đó, bằng chứng không kiến thức không thể giúp ích cho chúng.
Dựa vào "Bằng chứng về sự giàu có" để ngăn chặn các cuộc tấn công Sybil là không đủ để giải quyết vấn đề, vì vậy chúng ta cần một số hình thức hệ thống nhận dạng
Trong cộng đồng cypherpunk thuần túy, một giải pháp thay thế phổ biến là hoàn toàn dựa vào "bằng chứng về sự giàu có" để ngăn chặn các cuộc tấn công Sybil, thay vì xây dựng bất kỳ hình thức hệ thống nhận dạng nào. Bằng cách chịu một khoản chi phí nhất định cho mỗi tài khoản, có thể ngăn chặn mọi người dễ dàng tạo ra một số lượng lớn tài khoản. Thực hành này từ lâu đã là tiền lệ trên Internet. Ví dụ, diễn đàn Somethingawful yêu cầu một khoản phí một lần là 10 đô la để đăng ký tài khoản. Nếu tài khoản bị cấm, khoản phí sẽ không được hoàn lại. Tuy nhiên, đây không phải là mô hình kinh tế tiền điện tử thực sự trong thực tế, vì trở ngại lớn nhất để tạo tài khoản mới không phải là trả lại 10 đô la mà là nhận được một thẻ tín dụng mới.
Về mặt lý thuyết, thậm chí có thể thực hiện thanh toán có điều kiện: khi đăng ký tài khoản, bạn chỉ cần thế chấp một số tiền nhất định và chỉ mất số tiền này trong trường hợp hiếm hoi là tài khoản bị cấm. Về mặt lý thuyết, điều này có thể làm tăng đáng kể chi phí của một cuộc tấn công.
Cách tiếp cận này hiệu quả trong nhiều tình huống, nhưng lại không hiệu quả trong một số loại tình huống. Tôi sẽ tập trung vào hai loại tình huống, mà tôi sẽ gọi là "giống UBI" và "giống quản trị".
Nhu cầu về bản sắc trong một kịch bản giống như UBI
Cái gọi là "kịch bản bán UBI" đề cập đến một kịch bản mà một số lượng tài sản hoặc dịch vụ nhất định cần được phân phối cho một nhóm người dùng rất rộng (lý tưởng nhất là tất cả), bất kể khả năng thanh toán của họ. Worldcoin đang thực hành điều này một cách có hệ thống: bất kỳ ai có World ID đều có thể thường xuyên nhận được một lượng nhỏ token WLD. Nhiều đợt airdrop token cũng đạt được các mục tiêu tương tự theo cách không chính thức hơn, cố gắng đưa ít nhất một số token vào tay càng nhiều người dùng càng tốt.
Cá nhân tôi không nghĩ những token như vậy sẽ đủ giá trị để duy trì sinh kế của một người. Trong một nền kinh tế do AI thúc đẩy với sự giàu có gấp nghìn lần, những token như vậy có thể đáng để duy trì sinh kế, nhưng ngay cả khi đó, các chương trình do chính phủ lãnh đạo ít nhất được hỗ trợ bởi sự giàu có về tài nguyên thiên nhiên vẫn sẽ đóng vai trò quan trọng hơn trong nền kinh tế. Tuy nhiên, tôi nghĩ vấn đề mà những "mini-UBI" này thực sự có thể giải quyết là: cung cấp cho mọi người đủ tiền điện tử để hoàn thành một số giao dịch cơ bản trên chuỗi và mua hàng trực tuyến. Điều này có thể bao gồm:
- Nhận tên ENS
- Xuất bản một hàm băm trên chuỗi để khởi tạo danh tính bằng chứng không có kiến thức
- Thanh toán cho các nền tảng truyền thông xã hội
Nếu tiền mã hóa được áp dụng rộng rãi trên toàn thế giới, vấn đề này sẽ không còn nữa. Nhưng tại thời điểm tiền mã hóa chưa phổ biến, đây có thể là cách duy nhất để mọi người truy cập vào các ứng dụng phi tài chính và hàng hóa và dịch vụ trực tuyến liên quan trên chuỗi, nếu không, họ có thể không thể truy cập vào các tài nguyên này.
Nếu tiền mã hóa được áp dụng rộng rãi trên toàn thế giới, vấn đề này sẽ không còn nữa. Nhưng tại thời điểm tiền mã hóa chưa phổ biến, đây có thể là cách duy nhất để mọi người truy cập vào các ứng dụng phi tài chính và hàng hóa và dịch vụ trực tuyến liên quan trên chuỗi, nếu không, họ có thể không thể truy cập vào các tài nguyên này.
Một cách khác để đạt được hiệu ứng tương tự là thông qua “các dịch vụ cơ bản phổ quát”: cung cấp cho mọi người có danh tính khả năng gửi một số lượng giao dịch miễn phí giới hạn trong một ứng dụng cụ thể. Cách tiếp cận này có thể phù hợp hơn với động cơ và hiệu quả về vốn, vì mọi ứng dụng được hưởng lợi từ việc áp dụng như vậy đều có thể làm như vậy mà không phải trả tiền cho những người không phải là người dùng; tuy nhiên, nó đi kèm với sự đánh đổi là tính phổ quát giảm (người dùng chỉ được đảm bảo quyền truy cập vào các ứng dụng tham gia chương trình). Mặc dù vậy, vẫn cần có giải pháp danh tính để bảo vệ hệ thống khỏi các cuộc tấn công thư rác đồng thời tránh tính độc quyền xuất phát từ việc yêu cầu người dùng thanh toán thông qua phương thức thanh toán có thể không khả dụng với tất cả mọi người.
Hạng mục quan trọng cuối cùng đáng chú ý là "tiền gửi an ninh cơ bản phổ quát". Một trong những chức năng của danh tính là cung cấp một mục tiêu có thể được sử dụng để giải trình mà không yêu cầu người dùng phải thế chấp tiền tương xứng với quy mô của ưu đãi. Điều này cũng giúp đạt được mục tiêu: giảm sự phụ thuộc của ngưỡng tham gia vào số vốn cá nhân (hoặc thậm chí không yêu cầu vốn nào cả).
Nhu cầu về bản sắc trong các kịch bản giống như quản trị
Hãy tưởng tượng một hệ thống bỏ phiếu (như thích và đăng lại trên các nền tảng truyền thông xã hội): nếu người dùng A có nguồn lực gấp 10 lần người dùng B, thì quyền biểu quyết của người đó cũng sẽ gấp 10 lần B. Nhưng xét về góc độ kinh tế, lợi ích mang lại cho A trên mỗi đơn vị quyền biểu quyết gấp 10 lần so với B (vì A lớn hơn, tác động của bất kỳ quyết định nào ở cấp độ kinh tế của họ sẽ đáng kể hơn). Do đó, nhìn chung, phiếu bầu của A có lợi cho chính nó gấp 100 lần so với phiếu bầu của B. Vì điều này, chúng ta sẽ thấy rằng A sẽ đầu tư nhiều năng lượng hơn vào việc tham gia bỏ phiếu, nghiên cứu cách bỏ phiếu để tối đa hóa mục tiêu của riêng mình và thậm chí có thể thao túng thuật toán một cách chiến lược. Đây cũng là lý do cơ bản tại sao "cá voi" có thể có ảnh hưởng quá mức trong cơ chế bỏ phiếu bằng mã thông báo.
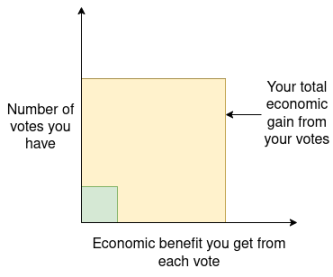
Một lý do sâu xa và tổng quát hơn là hệ thống quản trị không nên coi trọng "một người kiểm soát 100.000 đô la" như "1.000 người nắm giữ 100.000 đô la". Sau này đại diện cho 1.000 cá nhân độc lập, và do đó chứa thông tin có giá trị phong phú hơn thay vì mức độ lặp lại cao của một lượng thông tin nhỏ. Tín hiệu từ 1.000 người cũng có xu hướng "nhẹ nhàng" hơn vì ý kiến của những cá nhân khác nhau có xu hướng triệt tiêu lẫn nhau.

Điều này áp dụng cho cả hệ thống bỏ phiếu chính thức và “hệ thống bỏ phiếu không chính thức”, chẳng hạn như khả năng của mọi người trong việc tham gia vào quá trình phát triển văn hóa bằng cách lên tiếng trước công chúng.
Điều này cho thấy rằng một hệ thống bán quản trị sẽ không thực sự hài lòng khi đối xử với tất cả các bó có cùng kích thước như nhau, bất kể nguồn gốc của chúng. Thay vào đó, hệ thống sẽ cần hiểu mức độ phối hợp nội bộ giữa các bó này.
Cần lưu ý rằng nếu bạn đồng ý với khuôn khổ mô tả của tôi về hai kịch bản trên (kịch bản giống như thu nhập cơ bản toàn dân và kịch bản giống như quản trị), thì xét về góc độ kỹ thuật, nhu cầu về một quy tắc rõ ràng như "một người, một phiếu bầu" không còn nữa.
- Đối với các ứng dụng giống UBI, điều thực sự cần thiết là một giải pháp nhận dạng giúp danh tính đầu tiên trở nên miễn phí và giới hạn số lượng danh tính có thể có được. Hiệu ứng giới hạn đạt được khi chi phí để có thêm danh tính đủ cao khiến việc tấn công hệ thống trở nên vô nghĩa.
- Đối với các ứng dụng giống như quản trị, yêu cầu cốt lõi là có khả năng đánh giá thông qua một số chỉ số gián tiếp xem liệu các tài nguyên mà bạn tiếp xúc có được kiểm soát bởi một thực thể duy nhất hay một nhóm "được hình thành tự nhiên" có mức độ phối hợp thấp.
Trong cả hai trường hợp, danh tính vẫn rất hữu ích, nhưng không còn yêu cầu phải tuân theo các quy tắc nghiêm ngặt như "một người, một danh tính" nữa.
Trạng thái lý tưởng về mặt lý thuyết là: chi phí để có được N danh tính là N²
Từ những lập luận trên, ta có thể thấy có hai áp lực từ hai phía đối lập hạn chế độ khó mong muốn trong việc đạt được nhiều danh tính trong hệ thống danh tính:
Đầu tiên, không thể có giới hạn cứng rõ ràng và dễ thấy về số lượng danh tính dễ tiếp cận. Nếu một người chỉ có thể có một danh tính, sẽ không có sự ẩn danh và họ có thể bị ép buộc tiết lộ danh tính của mình. Trên thực tế, ngay cả một con số cố định lớn hơn 1 cũng là rủi ro: nếu mọi người đều biết rằng mọi người đều có 5 danh tính, bạn có thể bị ép buộc tiết lộ cả 5 danh tính.
Một lý do khác để ủng hộ điều này là bản thân tính ẩn danh rất mong manh, do đó cần có một vùng đệm an toàn đủ lớn. Với các công cụ AI hiện đại, có thể dễ dàng liên hệ hành vi của người dùng trên các nền tảng. Thông qua thông tin công khai như thói quen sử dụng từ ngữ, thời gian đăng bài, khoảng thời gian đăng bài và chủ đề thảo luận, chỉ cần 33 bit thông tin để khóa chính xác một người. Mọi người có thể sử dụng các công cụ AI để phòng thủ (ví dụ, khi tôi đăng nội dung ẩn danh, tôi đã viết bằng tiếng Pháp rồi dịch sang tiếng Anh thông qua một mô hình ngôn ngữ lớn chạy cục bộ), nhưng ngay cả như vậy, tôi không muốn hoàn toàn chấm dứt tính ẩn danh của mình chỉ bằng một lỗi duy nhất.
Thứ hai, danh tính không thể hoàn toàn gắn liền với tài chính (tức là chi phí để có được N danh tính là N), vì điều này sẽ khiến các thực thể lớn dễ dàng có được quá nhiều ảnh hưởng (và do đó khiến các thực thể nhỏ mất đi tiếng nói của mình hoàn toàn). Cơ chế mới của Twitter Blue phản ánh điều này: mức phí chứng nhận 8 đô la một tháng là quá thấp để hạn chế hiệu quả tình trạng lạm dụng và hiện tại người dùng về cơ bản đã bỏ qua dấu chứng nhận này.
Hơn nữa, chúng ta có thể không muốn một thực thể có lượng tài nguyên gấp N lần lại có thể tham gia vào nhiều hành vi không phù hợp hơn N lần mà không bị trừng phạt.
Để tóm tắt các lập luận trên, chúng tôi muốn làm cho việc có được nhiều danh tính trở nên dễ dàng nhất có thể trong khi vẫn đáp ứng các ràng buộc sau: (1) hạn chế quyền lực của các thực thể lớn trong các ứng dụng giống như quản trị; và (2) hạn chế lạm dụng trong các ứng dụng giống như UBI.
Nếu chúng ta trực tiếp tham khảo mô hình toán học của ứng dụng giống như quản trị trong bài viết trước, chúng ta sẽ có được câu trả lời rõ ràng: nếu có N danh tính có thể mang lại ảnh hưởng N², thì chi phí để có được N danh tính phải là N². Thật trùng hợp, câu trả lời này cũng áp dụng cho ứng dụng giống như thu nhập cơ bản phổ quát.
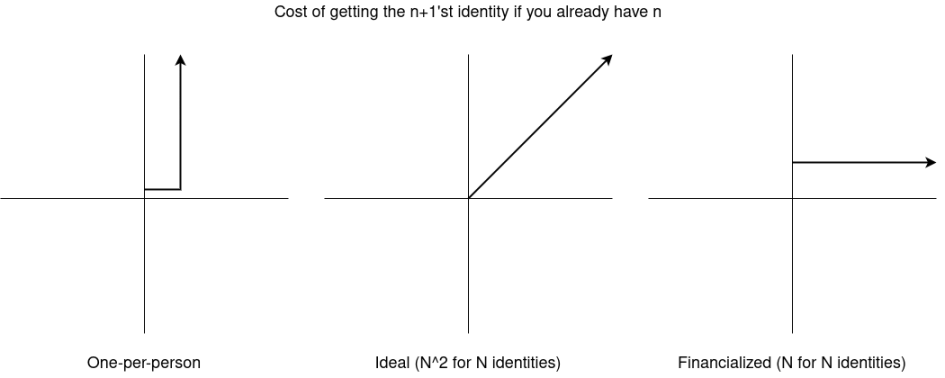
Những độc giả thường xuyên của blog này có thể nhận thấy rằng biểu đồ này hoàn toàn giống với biểu đồ trong bài đăng trước đó về “ nguồn tài trợ bậc hai ”, và đây không phải là sự ngẫu nhiên.
Bản sắc đa nguyên có thể đạt được trạng thái lý tưởng này
Cái gọi là "hệ thống đa danh tính" là cơ chế danh tính không có một cơ quan phát hành thống trị duy nhất, bất kể cơ quan đó là cá nhân, tổ chức hay nền tảng. Hệ thống này có thể đạt được theo hai cách:
- Bản sắc đa nguyên rõ ràng (còn được gọi là bản sắc dựa trên biểu đồ xã hội). Bạn có thể xác minh danh tính của mình (hoặc các khiếu nại khác, chẳng hạn như xác nhận rằng bạn là thành viên của một cộng đồng) thông qua việc xác nhận của những người khác trong cộng đồng của bạn và danh tính của những người xác nhận này được xác minh thông qua cùng một cơ chế. Bài viết "Xã hội phi tập trung" có mô tả chi tiết hơn về loại thiết kế này và Circles là một ví dụ hiện tại.
- Danh tính đa nguyên ngầm định. Đây là tình hình hiện tại. Có nhiều nhà cung cấp danh tính khác nhau, bao gồm Google, Twitter, các nền tảng tương tự ở nhiều quốc gia khác nhau và nhiều ID do chính phủ cấp. Rất ít ứng dụng chỉ chấp nhận một loại xác thực danh tính. Hầu hết các ứng dụng đều tương thích với nhiều loại vì chỉ theo cách này, chúng mới có thể tiếp cận được người dùng tiềm năng.

Ảnh chụp nhanh gần đây về biểu đồ nhận dạng Circles. Circles là một trong những dự án nhận dạng lớn nhất dựa trên biểu đồ xã hội.
Bản chất của đa danh tính rõ ràng là ẩn danh: bạn có thể có một danh tính ẩn danh (hoặc thậm chí nhiều danh tính), mỗi danh tính có thể xây dựng danh tiếng trong cộng đồng thông qua các hành động của mình. Một hệ thống đa danh tính rõ ràng lý tưởng thậm chí có thể không yêu cầu khái niệm "danh tính rời rạc"; thay vào đó, bạn có thể có một tập hợp mờ nhạt các hành động trong quá khứ có thể xác minh được và có thể chứng minh các phần khác nhau của nó theo cách chi tiết khi cần cho từng hành động.
Bằng chứng không kiến thức sẽ giúp đạt được tính ẩn danh dễ dàng hơn nhiều: bạn có thể sử dụng danh tính chính để bắt đầu danh tính ẩn danh, sau đó cung cấp tín hiệu đầu tiên một cách riêng tư để danh tính ẩn danh mới được nhận dạng (ví dụ: chứng minh rằng bạn sở hữu một số lượng mã thông báo nhất định để đăng trên anon.world hoặc chứng minh rằng những người theo dõi bạn trên Twitter có một đặc điểm nhất định). Có thể có những cách hiệu quả hơn để sử dụng bằng chứng không kiến thức.
"Đường cong chi phí" cho nhiều danh tính ngầm định dốc hơn đường cong bậc hai, nhưng vẫn có hầu hết các thuộc tính mong muốn. Hầu hết mọi người đều có một số, nhưng không phải tất cả, các danh tính được liệt kê ở đây. Bạn có thể có được một danh tính khác với một số nỗ lực, nhưng bạn càng có nhiều danh tính, tỷ lệ chi phí-lợi ích của việc có được danh tính tiếp theo càng thấp. Do đó, nó cung cấp các biện pháp ngăn chặn cần thiết cho các cuộc tấn công quản trị và các hành vi lạm dụng khác, đồng thời đảm bảo rằng những kẻ ép buộc không thể yêu cầu (và không thể mong đợi một cách hợp lý) bạn tiết lộ một tập hợp danh tính cố định.
Bất kỳ hình thức hệ thống nhận dạng đa dạng nào (dù ngầm hay công khai) đều có tính khoan dung hơn: những người khuyết tật ở tay hoặc mắt vẫn có thể giữ hộ chiếu và những người không quốc tịch vẫn có thể chứng minh danh tính của mình thông qua một số kênh phi chính phủ.
Điều quan trọng cần lưu ý là nếu một biểu mẫu nhận dạng duy nhất đạt 100% thị phần và trở thành tùy chọn đăng nhập duy nhất, các tính năng trên sẽ không thành công. Theo tôi, đây là rủi ro lớn nhất mà các hệ thống nhận dạng theo đuổi "tính phổ quát" quá mức có thể phải đối mặt: khi thị phần của nó đạt tới 100%, nó sẽ đẩy thế giới từ hệ thống đa nhận dạng sang mô hình "một người, một nhận dạng", mà như đã mô tả trong bài viết này, có nhiều nhược điểm.
Theo tôi, kết quả lý tưởng của dự án "một người một danh tính" hiện tại là hợp nhất với hệ thống danh tính dựa trên biểu đồ xã hội. Vấn đề lớn nhất mà các dự án danh tính dựa trên biểu đồ xã hội phải đối mặt là khó có thể mở rộng quy mô cho số lượng lớn người dùng. Hệ thống "một người một danh tính" có thể được sử dụng để cung cấp hỗ trợ ban đầu cho biểu đồ xã hội, tạo ra hàng triệu "người dùng hạt giống", và sau đó số lượng người dùng sẽ đủ lớn để phát triển an toàn một biểu đồ xã hội phân tán toàn cầu từ nền tảng này.
Xin chân thành cảm ơn các tình nguyện viên Balvi, các thành viên Lâm nghiệp và các thành viên nhóm World đã tham gia thảo luận.

Tất cả bình luận